User Research
How CYB uses Atomic Research to structure our insights
CYB’s User Researcher Truly Capell writes about how our team have incorporated Atomic Research into our practice - and how it is helping our clients

Here at Caution Your Blast Ltd (CYB) we’re always looking for new ways of working that can help us use digital as a force for good. For our research team, that means exploring avenues that allow us to better understand user needs and behaviours, which in turn helps our clients to make the best possible services and products.
My colleague Anita recently blogged about how we have created our own tailored Research Ops model that has helped our clients to improve their own research practices.
In Part 2, I am going to write about how CYB is using Atomic Research to gather and organise our facts, insights and recommendations.
What is Atomic Research?
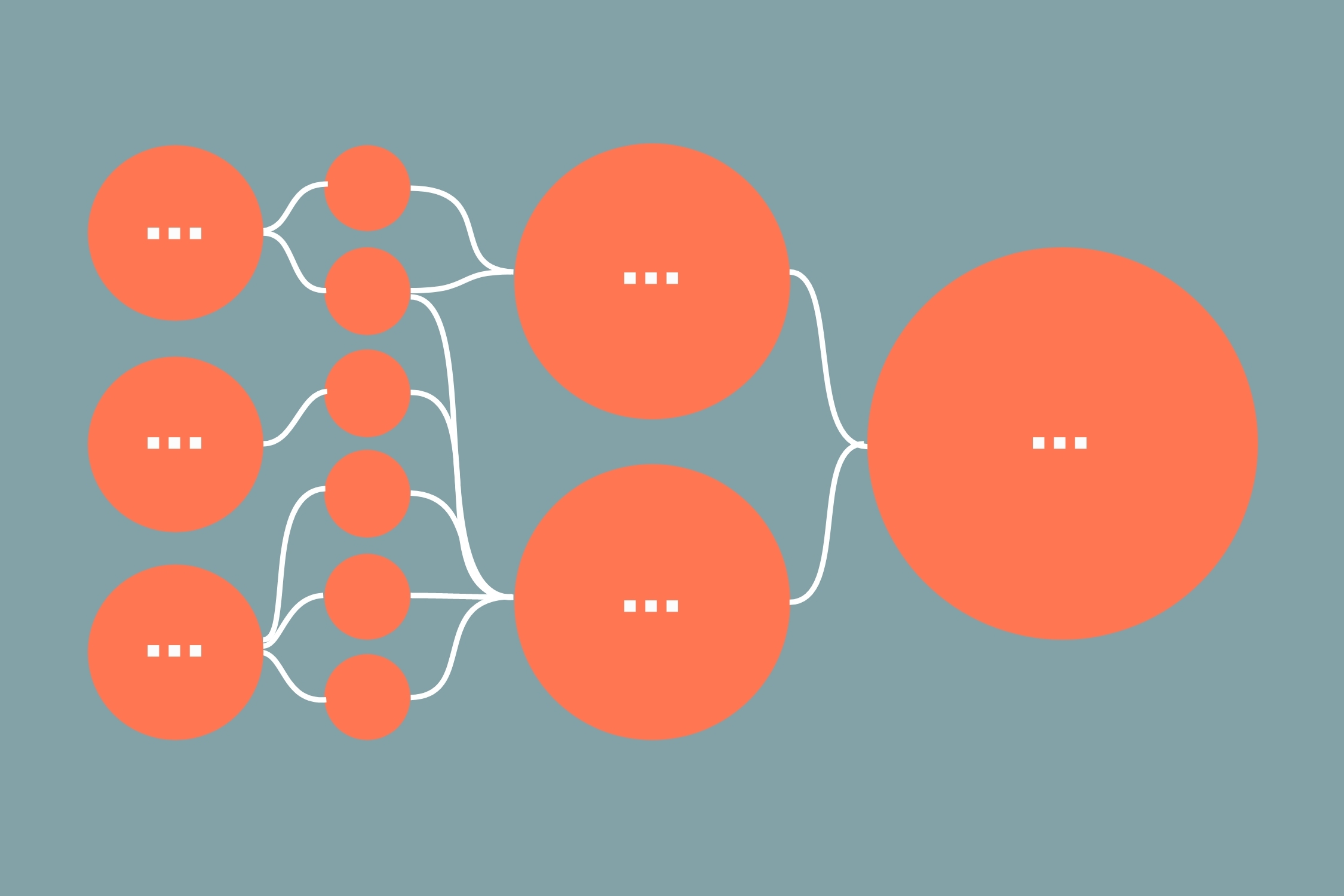
Atomic Research, developed by Daniel Pidcock, is a framework to distil your data, whether quantitative or qualitative, into facts that inform insights - which in turn inform recommendations. It essentially breaks down information into smaller pieces, enabling you to combine findings from different methods and rounds of research, making your insights more robust the more research you do.
Atomic Research naturally breaks down silos. Instead of pockets of research existing in reports, slides and handover documents, it exists in one ever-evolving repository that gets richer the more research you conduct.

Turning our data into facts
As a team, we tasked ourselves with investigating how we might use Atomic Research to best structure our research insights across projects at the Foreign, Commonwealth and Development Office (FCDO). We had just started an FCDO project that felt like the perfect candidate to try this out - the redesigning of the Emergency Travel Document (ETD) centre systems and processes, which looked to deliver a more efficient service to applicants and reduce potential for errors. British nationals abroad apply for ETDs if they have lost their passport and need to travel home quickly.
We had pockets of research from previous work on specific parts of the processes and for specific user groups - but now we were tasked with looking at the end-to-end process from every user who interacts with the service perspective. We had to figure out what we already knew about the process, and where our gaps in knowledge were. As a first step, we looked at what raw data we had. It turned out we had a lot.
Our pockets of research existed in different forms from our previous work, all of which we could piece together to understand the as-is process:
pain points spanning an end to end journey
quotes from interviews with users
descriptions of users behaviours from observational studies
usability testing reports
The first thing that stood out to us was our pain point data consisted of multiple nested facts within one statement. This took some untangling to turn our pain points into usable facts. For instance: this quote from a user interview - “allocating cases is a little clunky, you have to drag cases into the right folders and in the right order for first time applications” - actually buried 3 facts.
First, allocating cases takes multiple clicks; second, there are additional workarounds to allocate first time applications; and finally, that first time applications do not have the same workflow as other users.
On the reverse of that, we found multiple user quotes from interviews needed to be combined together to form a stand alone fact. For example: “the pending queue is messy” and “the pending queue is big because everything that isn’t progressing ends up in there, you get duplicates of applications in there too” together make up just one stand alone fact (“the pending queue is unstructured, it contains all types of applications and duplicate applications too”).
Given this, we realised we must add our own first step in Atomic Research for qualitative data - this way, we could ensure our facts were indeed stand alone facts. We went through a cleansing process in which we pieced together or untangled raw user data. By doing this, we were able to make the facts more usable across projects. We also found by spending time contextualising facts there was less “leg work” for other team members to get up to speed with our research. We could then start synthesising insights from our refined facts. The forming of the insights is where we started to get excited as a research team…
Visualising the relationship between facts and insights
We loved how we could visually explain the process we go through; from synthesising insights from a collection of facts, to gathering recommendations based on these findings. It's the first time we could visually show what data we have, where it’s come from and what we have learnt from that data. We could show the evidence we had for one user insight spanning an entire 4 metre long service blueprint, which involves multiple people and technologies.

This visual representation of how we take what happens in research sessions and turn it into evidence was very compelling for stakeholders. When we were playing back our findings during workshops our stakeholders were impressed with how much we had learnt in 6 weeks.
Displaying our processes and thinking more transparently allowed them to trust more in our recommendations. This resulted in co-ideation together between FCDO stakeholders in varying business areas and ourselves on what the future could look like given what we found out.
Atomic Research allowed them to more quickly understand what was happening and why, and therefore made it easier to make decisions based on our research findings. We left the workshop with prioritised areas for improvement along with potential solutions that as a team we further developed, understanding technically how we would get there.
What we’re doing with the insights
Overall, we have been really pleased with how well Atomic Research worked for us. By doing this work, we could see how structuring the data lends itself to being stored in a research library. We’re now exploring the best way to create the library so that we can easily find and surface all types of research that we do at CYB.
I will blog again soon to tell you how this went, what we’ve learnt and how we’ve progressed our thinking on Atomic Research to create insight libraries. Watch this space!